


OpenAI’s ARC de Triumph
How a puzzle designed to resist memorization is reshaping AI intelligence tests. See if you can score better than an AI model.
OpenAI’s Sam Altman thinks that the upcoming GPT-5 AI model will be smarter than him. Emphasis ours:
“I don’t think I’m going to be smarter than GPT-5. And I don’t feel sad about it because I think it just means that we’ll be able to use it to do incredible things.”
But what does it actually mean for an AI to be “smart”? It turns out this is pretty difficult to nail down, as the AI world can’t even decide what the definition of “artificial general intelligence” (AGI) is. While imperfect, the industry has embraced the use of “benchmarks” — tests designed to measure an AI model’s knowledge and reasoning ability.
Want to test how well an AI model can write code? There’s a benchmark for that: SWE-bench. High school math? AIME 2024. General knowledge across multiple subjects? MMLU.
AI companies are quick to boast about how well their new model tested on different benchmarks, using them as proof of progress. But recently, a new high score for one of the most challenging benchmarks caught the industry’s attention.
Unlike traditional benchmarks filled with multiple-choice questions, ARC-AGI is unique and challenges AI with purely visual puzzles designed to test complex reasoning skills. For five years, no AI model could score higher than 5% on the test.
That changed when OpenAI announced on December 20, 2024, that its just-released “o3” model had solved the ARC-AGI test. This marked the first time any AI had passed the test — a huge leap over the other state-of-the-art models.
François Chollet, an AI researcher and cofounder of new AI startup Ndea, created the ARC-AGI challenge in 2019. When asked about the significance of OpenAI’s breakthrough score on his test, Chollet called it “a major achievement.”
In an email to Sherwood News, Chollet noted that OpenAI’s previous GPT models all scored near zero on the test. “It demonstrates the fact that o3 is not limited to memorized skills and memorized knowledge, unlike the GPT series, or really unlike any prior major AI system. It is actually capable of adapting to novelty, at least in the very simple context of ARC-AGI tasks,” Chollet said.
Many of the previous testing tools failed to demonstrate what Chollet considers actual intelligence: “the ability to adapt on the fly to new situations and new problems. Rather they demonstrated memorized skill,” Chollet said.
Input > Output
So what does this test look like? It’s a series of tasks comprised of visual puzzles. The puzzle is made up of a series of colored tiles on a grid, with the computer reading each color as a different number.
Each task shows the test-taker a series of problem and solution pairs — the input and the output. The user has to look at the sample pairs and deduce the steps needed to solve these puzzles. Then the user is asked to solve a puzzle that only shows the input, applying the same solution from the examples.
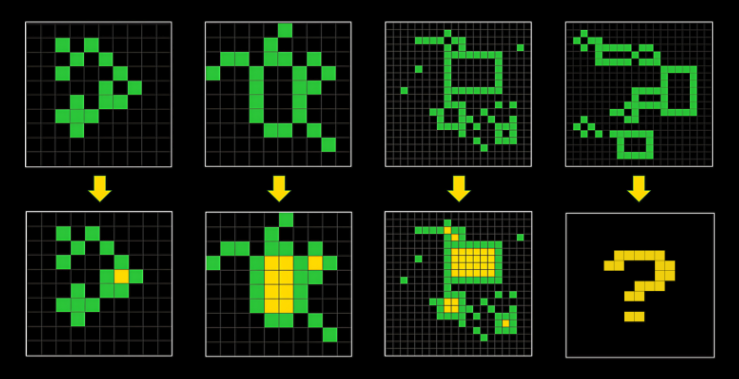
Chollet says the test was designed to not require any special training, but only innate “core knowledge” like object persistence, basic geometry, numbers and counting, and that objects can be animate or inanimate.
“Most of the puzzles are elementary, something a young child could figure out,” Chollet explained. “There’s just one thing: it’s designed to resist memorization. Each task is unique. You must figure out each task on the fly.”
Note: this quiz is optimized for desktop and is best viewed on a computer.
OpenAI shared the results of its testing with Chollet, which he has verified. The company has not yet released the full results of the testing for the community to assess. The results we can see require some unpacking, though.
According to Chollet, the test was done in several parts. One test used a “high efficiency, low cost” computing process. This cheaper, low-compute mode test scored an impressive 76%, which beat all previous records, but did not achieve the 85% passing score. The time it took for each puzzle to be solved was 1.3 minutes on average and it cost about $20 per puzzle in computing power to solve each one.
But when OpenAI cranked it up and used the “low efficiency, high cost” process, it scored a winning 88% on the test. According to Greg Kamradt, president of the nonprofit ARC Prize Foundation — which develops and funds benchmarks like ARC-AGI — human performance on the test is about 85%. To achieve such a high score, OpenAI’s model had to work really hard and it cost exponentially more.
On average, the most computing-intensive test took 13.8 minutes of “thinking” for each puzzle. That’s a lot of time for some expensive GPUs, like Nvidia’s popular H100 chip, and all that thinking isn’t cheap.
The cost to solve each puzzle was about $3,400, according to estimates from Chollet.
In January 2025, shortly after the release of DeepSeek’s R1 “reasoning” model, the foundation announced that the new model scored about as well as OpenAI’s “o1-preview” model, scoring a 20% on the test, but only costing $0.05 per puzzle on average.
Yesterday, OpenAI released GPT-4.5, the last “non-reasoning” model the company will release, and you might see why. The new model achieved a score of only 10% (for $0.29 per task).
As the industry grapples with a possible plateau of the AI “scaling law” that fueled the first wave of the generative-AI boom, a consensus is emerging that multistep reasoning like that found in o3 and DeepSeek R1 is going to be an important part of future performance gains. But as these test results show, longer, more intensive AI computing also drastically increases the costs — both fiscal and environmental.
Big Tech is planning on huge demand for this type of energy-thirsty computing, and intends to spend $315 billion this year alone on AI data centers and computing infrastructure.
But… is this AGI?
In the 2019 research paper in which Chollet proposed the ARC dataset, he speculated about the capabilities of an advanced AI system that could one day solve the test.
“We posit that the existence of a human-level ARC solver would represent the ability to program an AI from demonstrations alone (only requiring a handful of demonstrations to specify a complex task) to do a wide range of human-relatable tasks of a kind that would normally require human-level, human-like fluid intelligence,” Chollet wrote, emphasis ours.
While it’s not clear that any AI has reached this level of intelligence yet, it is clear that new benchmarks will be needed to test new models emerging from the fast-moving AI development pipeline. The ARC foundation is currently funding development of ARC-AGI-2, which will be released in March, as well as ARC-AGI-3, which will look more like simple animated 8-bit video games.
The ARC-AGI-2 benchmark was designed specifically to be difficult for these new “reasoning” models, but still easy for humans to solve. Today, humans appear to have the advantage, but the rapid pace of progress suggests that won’t last forever.
OpenAI did not return a request for comment.


