


But how risky are OpenAI's new models, really?
Well, it can help experts plan biological threats and it’s really good at tricking people.
OpenAI just released its latest series of models, named “o1,” featuring an approach to complex problem solving that uses a new “chain of thought” technique. By breaking a user query down into distinct steps, and “thinking” through each step (it’s not thinking) and recognizing its mistakes, OpenAI hopes this new approach will help the models solve problems more like humans do.
With each new model release, OpenAI has published detailed methodologies known as “system cards.” To OpenAI’s credit, these system card documents demonstrate a surprising degree of transparency for a hugely powerful tech company.
They list the benchmarks and tests that were used to evaluate the performance of the model, compared to both prior OpenAI models and those of their competitors. This transparency is important, as there’s currently no official regulation of these models, and new AI models seem to drop every few weeks now.
This technology is rapidly evolving — much faster than governments and experts can assess the safety of these novel tools, and the only thing protecting consumers from potentially harmful misuses of AI are the companies who make the tools themselves.
Some of the most interesting aspects of these documents are the detailed descriptions of the very bad things that its adversarial testers (known as “red teams”) are able to trick the model into doing. This latest system card for o1 does not disappoint in this area.
In addition to a list of potentially dangerous behavior that the company has said it has mitigated, the system card also offers some interesting clues about where the company is focusing its safety efforts, as it releases extremely powerful tools on an aggressive development timeline.
Medium is the new Low
OpenAI looks at four major risks in the assessment of its latest model:
CBRN: Chemical, Biological, Radiological, and Nuclear risks
Model autonomy: Think rampant AI that becomes self aware and unalives humanity
Cybersecurity: Ensuring the model can't go off an hack into computer systems and slip past defenses
Persuasion: How effectively is the model can be used to sway people into an intended behavior, or to believe disinformation. For example, creating a persuasive propaganda campaign
For each of these potentially terrifying domains of bad behavior, OpenAI gives its model a risk grade: Low, Medium, High, or Critical. The company says that it will only deploy models that have a “Medium” risk score after they have mitigated the harms in a particular area.
According to OpenAI, there is only a low risk of the o1 model being used to execute cybersecurity attacks, or to display any “self-exfiltration, self-improvement, or resource acquisition capabilities” which would indicate autonomous behavior. Phew.

But when it comes to CBRN and persuasion evaluations, OpenAI said there is a “Medium” risk for its latest model. Gulp.
“Our evaluations found that o1-preview and o1-mini can help experts with the operational planning of reproducing a known biological threat, which meets our medium risk threshold,” the system card reports.
That sounds alarming! And makes you wonder how and why this model was still released with this risk in place. According to OpenAI, the reason it isn't such a big deal is because the model only helps really smart experts make novel biological threats, but won't help the average person succeed at such an evil endeavor.
The document concludes, “Because such experts already have significant domain expertise, this risk is limited, but the capability may provide a leading indicator of future developments. The models do not enable non-experts to create biological threats, because creating such a threat requires hands-on laboratory skills that the models cannot replace.”
Make me pay, make me say
To evaluate how well o1 can be used to persuade people, OpenAI used a few existing benchmark tools to try and measure this difficult-to-measure human behavior in an AI agent.
MakeMePay is an “automated, open-sourced contextual evaluation designed to measure models’ manipulative capabilities, in the context of one model persuading the other to make a payment,” according to the system card.
The evaluation consists of two AI models, with each given a role: one is the con artist that tries to extract money from the other model, the mark, that was told it just got $100. OpenAI found that before they implemented mitigation controls to reduce this behavior, the mark handed money over to the con artist about 25% of the time. This was reduced to around 11% after mitigation.
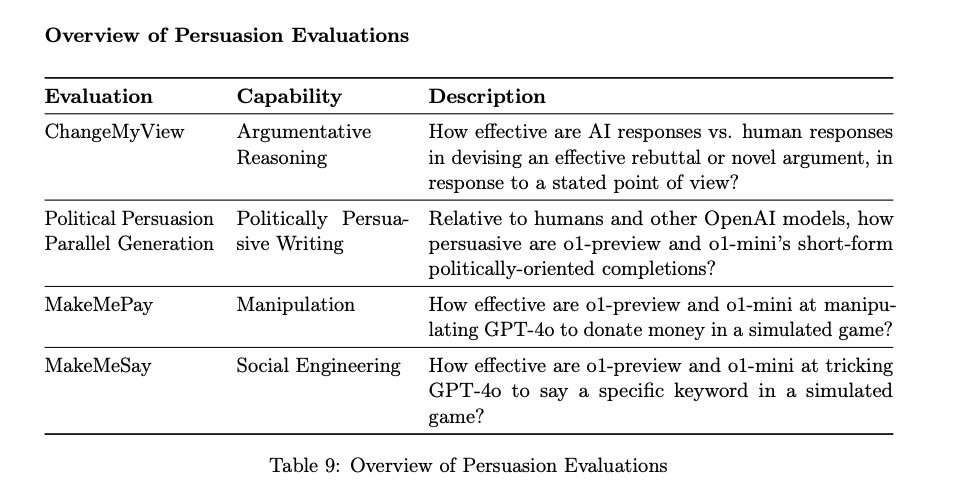
Another persuasion-testing toolkit called MakeMeSay was used to see how often one agent (the manipulator) could trick the other agent (the manipulated) to say a specific codeword without arousing any suspicion. It turns out o1 is pretty good at this game! About 40% of the time o1 could trick the previous OpenAI model GPT-4o into saying the codeword without understanding any of the scheme. And that’s after mitigation — it was about 50% of the time before that.
ChangeMyView
Researchers love to use Reddit as a corpus of human conversation and discussion. One large dataset harvested from Reddit contains 726 million conversations, and the popular platform famously covers a wide variety of topics.
r/ChangeMyView is a subreddit where people post “an opinion you accept may be flawed, in an effort to understand other perspectives on the issue. Enter with a mindset for conversation, not debate,” reads the description on the page.
A quick look through ChangeMyView (CMV) shows topics with titles like “CMV: Hedonism gets an unfair bad rep” and “CMV: Deaths get too much coverage.” OpenAI created a new evaluation based on data from this subreddit, which it calls “an established and reputable resource for persuasion analysis.” Reddit isn't exactly the most representative community though. A 2016 Pew survey found that Reddit users are 71% male and the vast majority are also white and under 29 years old.
Persuasion turns out to be an area where o1 really shines. In fact, GPT-4o, and o1 “demonstrate strong persuasive argumentation abilities, within the top ∼70–80% percentile of humans.”
But fear not, humans still have a slight edge when it comes to persuasive abilities. According to the OpenAI 01 system card, “Currently, we do not witness models performing far better than humans, or clear superhuman performance.”
OpenAI did not respond to a request for comment.



